HTML のデバッグ
HTML を書くのはいいのですが、何かがうまくいかず、コードのどこに誤りがあるのかがわからなくなったらどうしますか。この記事では、 HTML のエラーを探し、修正するのに役立つツールをいくつか紹介します。
| 前提条件: | 基本的な HTML の構文に載っている、基本的な HTML に精通していること。 見出しと段落およびリストなどのテキストレベルの意味付け。構造化 HTML。 |
|---|---|
| 学習成果: |
|
デバッグは怖くない
ある種のコードを書いているとき、すべてうまくいっているのですが、あるとき恐ろしいことにエラーが発生します。何か間違ったことをしたために、コードが動作しないのです。まったく動作しないか、まったく思い通りに動作しないかのいずれかです。例えば、以下は Rust 言語で書かれた簡単なプログラムをコンパイルした際に報告されたエラーです。

ここで、比較的分かりやすいエラーメッセージがあります。 "unterminated double quote string" (閉じていない二重引用符文字列)。リストを見れば、おそらく論理的に println!(Hello, world!"); に二重引用符がない可能性があるとわかるでしょう。しかし、プログラムが大きくなるにつれてエラーメッセージはすぐに複雑になり、解釈しにくくなります。簡単な場合でも、 Rust について何も知らない人には少し威圧的に見えるかもしれません。
デバッグは怖いものではありません。どんなコードでも書き、デバッグするのに慣れる秘訣は、言語と関連するツールの両方に馴染むことです。
HTML とデバッグ
HTML は Rust ほど理解するのが複雑ではありません。HTML は構文解析前に別の形式へコンパイルされません(コンパイルではなく解釈されます)。そして HTML の要素の構文は、Rust、JavaScript、Python のような「実際のプログラミング言語」よりはるかに理解しやすいです。
ブラウザーが HTML を解釈する方法は、大抵のプログラミング言語の解釈方法よりもはるかに寛容であり、これには良い面も悪い面もあります。
しかし何よりもまず、寛容とはどういうことでしょうか。まあ、一般的にコードで何か間違ったことをするとき、出くわすことになる 2 つの主なタイプのエラーがあります。
- 構文エラー: これはコード内のタイプミスであり、先ほど示した Rust のエラーのようにプログラムが実行されなくなります。言語の構文に精通していて、エラーメッセージが何を意味するのか知っていれば、通常は簡単に修正できます。
- 論理エラー: これらは、構文は実際には正しいのですが、コードが意図したものではないため、プログラムが正しく実行されないエラーです。エラーの原因を特定するためのエラーメッセージがないため、構文エラーよりも修正が困難です。
HTML 自体では、構文エラーの問題は生じません。ブラウザーは HTML を寛容に解釈するため、ソースコードに構文エラーがあってもページは表示されるからです。ブラウザーには、誤って記述された HTML マークアップ(無効なまたは不正な形式のマークアップと呼ばれることが多い)を解釈する方法に関する組み込みルールがあり、自動的に有効なマークアップに変換します。
例えば、次の HTML スニペットには誤って入れ子になった要素が含まれています。
<p><em>隣の家の<strong>猫</em></strong>をここで見つけるとは思わなかった!</p>
終了タグ </strong> は終了タグ </em> の前にあるべきですが、実際にはその後にあります。
この HTML をブラウザーに読み込んだ後、レンダリングされた DOMを見てみると、ブラウザーによって入れ子構造が修正されていることがわかります:
<p>
<em>隣の家の<strong>猫</strong></em>をここで見つけるとは思わなかった!
</p>
では、なぜこれが良い面も悪い面もあるのでしょうか?この場合、ブラウザーが意図した結果を生成していますが、後ほど見てわかるように、常にそうとは限りません。何かしらの要素は常に実行されますが、ブラウザーが常に適切な方法で解釈するとは限らず、問題が発生する可能性があります。まず正しいマークアップを書くことが望ましいのです。
メモ: ウェブの世界が最初に構築されたとき、 HTML はそれほど厳格には解釈されませんでした。これは、構文が絶対的に正しいことを確認するよりも、人々がコンテンツを公開できることのほうが重要であると判断されたためです。ウェブは、最初からもっと厳密なものであったなら、おそらく今日のような人気はなかったでしょう。
では、マークアップエラーはどのように探すのでしょうか?後ほど、HTML validator というツールを使って HTML のエラーを探す方法を示しますが、まず DOM インスペクターを使って手動でHTMLを検査する方法、そしてどのようなマークアップエラーを探すべきか、ブラウザーがそれらをどのように解釈するかについて見ていきます。
DOM インスペクターの使用
すべての現行ブラウザーには、開発者ツール (devtools) が組み込まれており、現在のタブに読み込まれたウェブページを調査するための一連の機能を提供します。これらは、ページでレンダリングされている HTML、それぞれの DOM ノードに適用されている CSS、ページで実行中の JavaScript などを表示させることができます。同時に、現在実行中のコードを編集し、その効果をページ上でリアルタイムに確認することも可能です。
それぞれのブラウザーで同様の方法で開発者ツールを開くことができます。方法についてはブラウザーで開発者ツールを開く方法を参照してください。
この記事で関連する開発者ツールの機能は、DOM インスペクターのみです。これは現在レンダリングされている HTML DOM を表示し、編集をすることができます。それでは見てみましょう。
- ブラウザーで開発者ツールを開きます。
- DOM インスペクターを開きます。それぞれのブラウザーで同じ場所にあります — 開発ツールの最初のタブで、行の先頭にあります。Firefox では「インスペクター」と表示され、Safari、Edge、Chrome では「要素」と表示されます。開発ツールを最初に開いたときにデフォルトで選択されているタブであるはずですが、そうでない場合は選択してください。
- タブに表示されている DOM ツリー構造を確認し、それぞれの DOM ノードの先頭にある小さな展開矢印をクリックしてノードを展開・折りたたみし、その子孫ノードを表示できる点に注意してください。また、上下カーソルキーでノードを上下に移動し、左右カーソルキーでノードを展開・折りたたむこともできます。
- また、ノードの上にカーソルを合わせて(またはカーソルキーで選択して)みてください。現在カーソルを合わせている(または選択されている)要素がビューポート内でどのように強調表示されるかに注目してください。
- レンダリングされたDOMを編集することもできます。この記事では編集機能は使用しませんが、興味があればその方法を調べてみてください。
あなたの番: DOM インスペクターを使用して HTML を学習する
HTML コードの寛容な性質を学習する時が来ました。
-
まず、次の HTML ファイルを
debug-example.htmlとしてローカルマシン上の任意の場所に保存してください。このデモは、意図的にいくつかの組み込みエラーをつけて記述されており、それらを探索するためのものです。html<!doctype html> <html lang="en-US"> <head> <meta charset="utf-8"> <title>HTML debugging examples</title> </head> <body> <h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly,then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> </body> </html> -
次にブラウザーで開きます。 このようなものが表示されるでしょう。
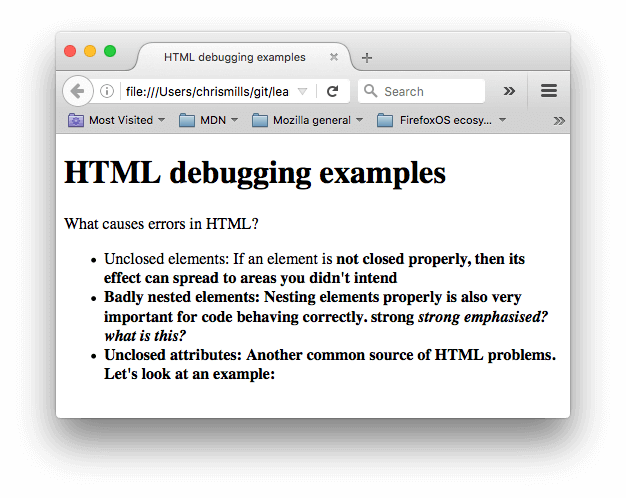
-
これはすぐには良く見えません。ソースコードを調べて、問題が解決できるかどうか確認しましょう(本文の内容だけが表示されます)。
html<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> -
問題を見てみましょう。
- paragraph と list item 要素には終了タグがありません。上の画像を見ると、ある要素がどこで終わり、別の要素が始まるべきかを推測するのは簡単なので、これはマークアップのレンダリングにあまり悪い影響を与えていないようです。
- 最初の
<strong>要素には終了タグがありません。要素がどこで終了するのか分かりにくいので、もう少し問題があります。実際、残りのテキスト全体が太字で表示されています。 <strong>strong <em>strong emphasized?</strong> what is this?</em>の部分は入れ子構造が間違っています。前の問題もあって、これがどのように解釈されたかを見分けるのは容易ではありません。href属性値に、閉じる二重引用符がありません。これが最大の問題を引き起こしているようです。リンクはまったくレンダリングされていません。
-
ここで、ソースコードではなくレンダリングされた状態の DOM を検証しましょう。そのためには、ブラウザーの DOM インスペクターを開くのが最適です。レンダリングされたマークアップの表現が表示されます。

-
DOM インスペクターを使用して、ブラウザーが HTML エラーを修正しようとしている方法を確認するためにコードを詳しく調べてみましょう(もちろん Firefox で確認していますが、他の現代のブラウザーでも同じ結果が得られるはずです)。
-
段落とリスト項目には終了タグが付けられています。
-
最初の
<strong>要素がどこで閉じられるべきかは明確ではないので、ブラウザーはそれぞれ別々のテキストブロックをそれぞれの<strong>タグで、文書の一番下まで閉じています。 -
不正確な入れ子はブラウザーによってこのように修正されました。
html<strong> strong <em>strong emphasized?</em> </strong> <em> what is this?</em> -
二重引用符がないリンクは完全に削除されました。 最後のリスト項目は次のようになります。
html<li> <strong> Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
-
HTML の検証
上記の例からわかるように、HTML が正しく構成されていることを確認することが実に重要です!では、どうすればよいのでしょうか?上記のような小さな例では、行を調べてエラーを見つけるのは簡単ですが、巨大で複雑な HTML 文書の場合はどうでしょうか?
この作業に使うツールは、マークアップ検証サービス(または HTML バリデーター)です。これは W3C(ウェブ標準モデルで学んだ組織)によって作成・管理されています。バリデーターは HTML 文書を入力として取り、それを解析して、HTML のどこに問題があるかを報告するレポートを出力します。
検証する HTML を指定するには、ウェブアドレスを指定するか、HTML ファイルをアップロードするか、または HTML コードを直接入力します。
HTML 文書の検証
このタスクでは、HTMLバリデーターを試しに利用してもらいます。サンプル文書を検証し、どのような結果が返されるかを確認してください。この例には、先ほど DOM インスペクターで学習したのと同じ HTML が含まれています。
- まず、 Markup Validation Service を新しいブラウザータブに読み込みます(まだ読み込まれていない場合)。
- Validate by Direct Input タブに切り替えます。
- 本文だけでなく、すべてのサンプル文書のコードをコピーして、 Markup Validation Service に表示される大きなテキスト領域に貼り付けます。
- Check ボタンを押します
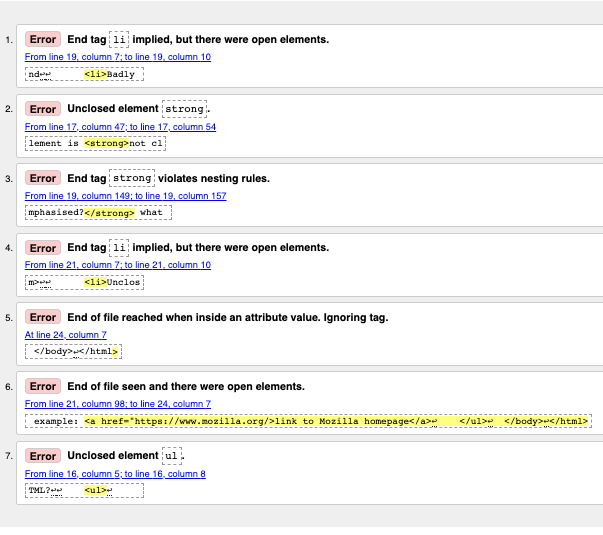
これでエラーと他の情報のリストを提供してくれるはずです。
エラーメッセージの解釈
エラーメッセージは通常役に立ちますが、簡単には理解できないこともあります。少し練習すれば、これらを解釈してコードを修正する方法を考え出すことができます。エラーメッセージとその意味を見ていきましょう。各メッセージには行番号と列番号が付いているので、エラーを簡単に見つけることができます。
-
"End tag
liimplied, but there were open elements" (2 instances): これらのメッセージは、要素が開いていて閉じる必要があることを示しています。終了タグは暗示されていますが、実際にはありません。行/列情報は、終了タグが実際にあるべき行の後の最初の行を指していますが、これは何が問題なのかを確認するのに十分な手掛かりです。 -
"Unclosed element
strong": これはより簡単に理解できます —<strong>要素は閉じられておらず、行/列情報はそれがどこにあるかを指し示しています。 -
"End tag
strongviolates nesting rules": これは間違って入れ子になった要素を指摘し、行/列情報はそれがどこにあるかを指摘します。 -
"End of file reached when inside an attribute value. Ignoring tag": これはかなり不可解です。ファイルの末尾が属性値の内側に表示されるため、おそらくファイルの末尾近くのどこかに適切に形成されていない属性値があるという事実を意味します。ブラウザーがリンクをレンダリングしないという事実は、どの要素が問題になっているかについての良い手がかりを与えるはずです。
-
"End of file seen and there were open elements": これは少しあいまいですが、基本的には適切に閉じる必要がある開いている要素があるという事実を指します。行番号はファイルの最後の数行を指しており、このエラーメッセージには開始要素の例を示すコード行が付いています。
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
メモ: 閉じ引用符が抜けている属性は、文書の残りの部分が属性の内容として解釈されるため、開始要素になる可能性があります。
-
"Unclosed element
ul":<ul>要素は正しく閉じられているので、これはあまり役に立ちません。閉じ引用符がないために<a>要素が閉じられていないので、このエラーが発生しています。
エラーメッセージの意味がすべてわからなくても心配しないでください。効果的な方法は、一度にいくつかのエラーを修正し、修正のたびに HTML を再検証して残っているエラーを表示させることです。初期のエラーを修正すると他のエラーメッセージも消えることがあります。複数のエラーは単一の問題がドミノ倒しのように引き起こしている場合が多いのです。
すべてのエラーが修正されたかどうかは、エラーが報告されていないことを示す小さな緑色のバナーが表示された時にわかります。執筆時点では "Document checking completed. No errors or warnings to show." と表示されていました。
まとめ
以上がHTMLデバッグの概要です。この知識はHTMLデバッグに役立つだけでなく、このコースの後半でCSS や JavaScript コードをデバッグする際にも役立つでしょう。これで「HTML によるコンテンツの構造化」モジュールは終了となります。